




AWS Lambda has become a popular mechanism for running code on-demand without the hassle of provisioning infrastructure. The merits of this service have been discussed at several fora on the web. Without delving much into what has already been brought out, we shall look at possible ways to mitigate cold starts when employing Lambda.
AWS docs define Lambda as:
a compute service that lets you run code without provisioning or managing servers. AWS Lambda executes your code only when needed and scales automatically, from a few requests per day to thousands per second.
Emphasised portion in the definition above brings out a significant aspect of Lambda's working. In one of their early blogs , AWS revealed:
AWS Lambda functions execute in a container
Further based on their 2018 re:Invent presentation, Firecracker might have replaced the containerisation process. Nonetheless, the bane of cold start remains. We can conclude that the root cause for a cold start is the process of provisioning a container (or a microVM) and setting up the run time environment required to execute our code.
It has been observed that the cold start times are about 3 to 5 seconds, when the Lambda function is outside of a VPC. If inside a VPC, the problem aggravates severely. Latency can range from 12 to 18 seconds. An insightful and scientific study has been published here, here and here . These times are unacceptable for many use cases.
Ah...before we get further, did we define what a Cold Start is? Simply put, it is the latency in the first response of a newly minted Lambda function. Keywords are in bold! As explained by Yan Cui in his blog , cold start is not just the first time a Lambda function is invoked; it is every time a Lambda function instance needs to be provisioned and the newly provisioned instance's first request has to be served. Now, it is not in our control as to when a new Lambda function instance gets provisioned. Well, that's the compromise for not having to set up your own server! To get something, one has to give something! (Well, in this case "give up" :))
So, how do we mitigate this problem?
Several solutions have been proposed. e.g, here and here. AWS itself provides CloudWatch Events to help keep your Lambda function warm.
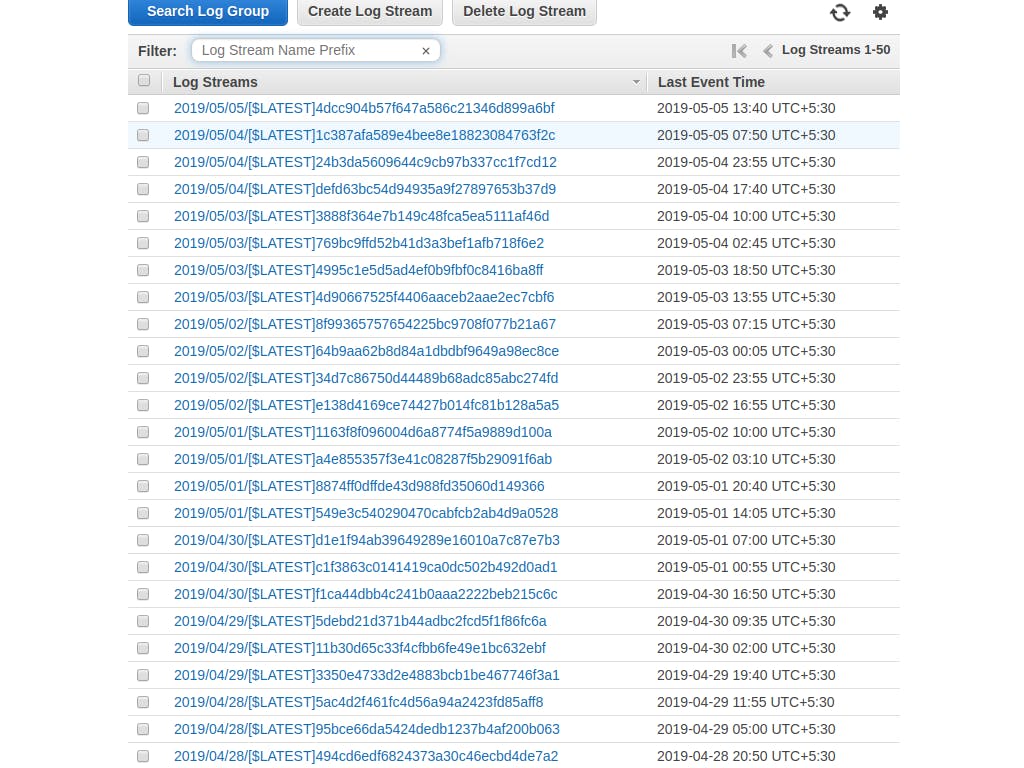
Complex problems warrant simple solutions! In the context of API Gateway + Lambda, this author experimented with several of the options presented above and found out that a simple cron to ping the API Gateway periodically did the trick! The key is in identifying the frequency of pinging. By experimentation, I have arrived at a 5 min ping frequency was optimal in keeping the Lambda warm. As seen in the screenshot below, the number of new instances brought up per day is just 3 or 4. Be aware that AWS compulsorily retires an instance after a set duration. In my experiment, I have been able to hold on to an instance for up to 8 hours.
Feel free to share your insights!